【CVPR '25】Linear Attention Modeling for Learned Image Compression
1. Info
Title: Linear Attention Modeling for
Learned Image Compression
Author: Donghui
Feng
Pub: CVPR 2025
Repo: https://github.com/sjtu-medialab/RwkvCompress
Keyword: RWKV, Checkboard
2. Motivation
- 现有LIC多关注强建模能力的Backbone设计,忽略了低复杂度设计。
- Transformer存在二次复杂度问题,线性注意力(如Mamba、RWKV)可降低计算成本,但还未用于LIC中
3. Contribution
- 首次将线性注意力模型RWKV引入到LIC领域中:设计高校特征提取模块Bi-RWKV Block,通过“空间混合+通道混合+Omni-Shift“的协同设计实现紧凑特征提取。
- 提出RWKV-SCCTX上下文建模模型。从空间维度、通道维度进行混合,优化建模效率。
4. Method
4.1 Overview
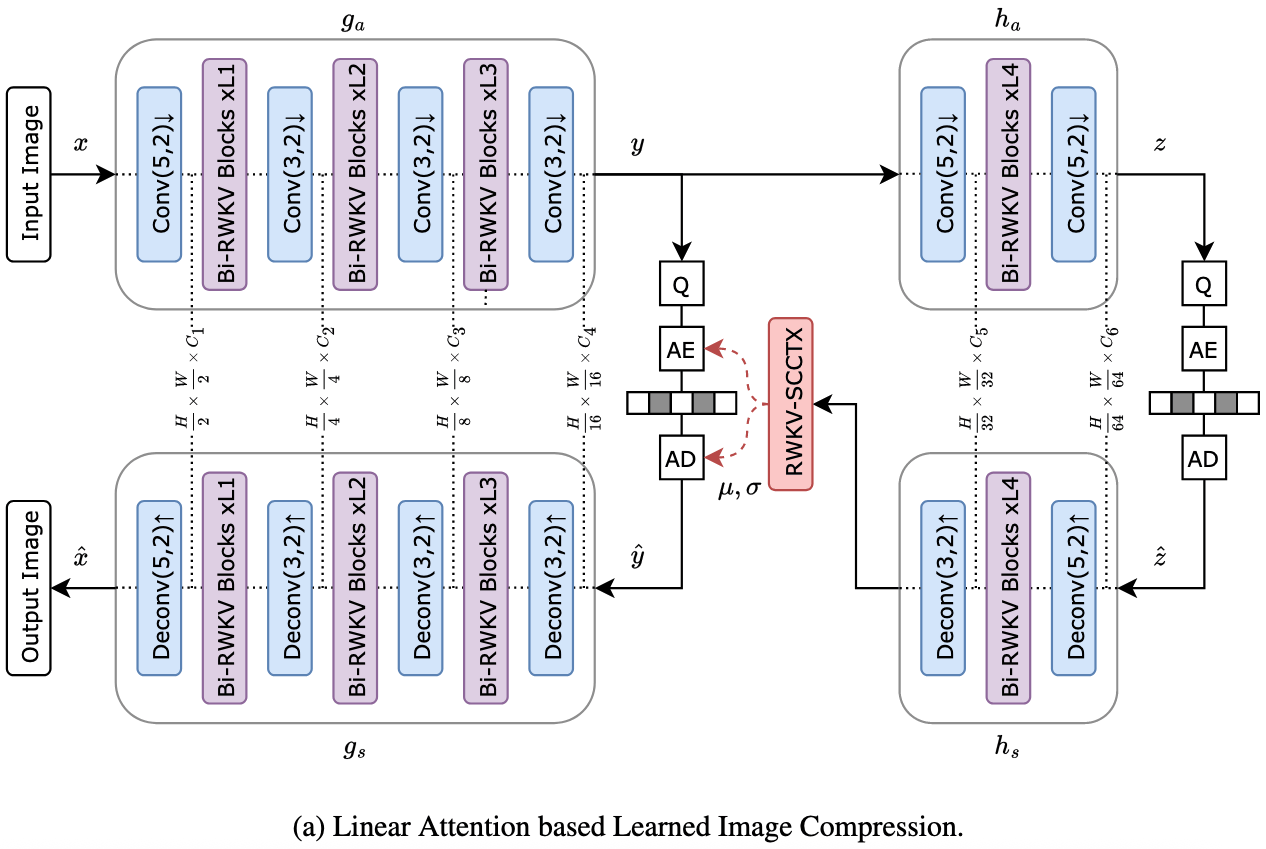 从图可以看出,其RWKV改进的地方也是变换网络和熵建模两个关键部分。两个核心设计是Bi-RWKV
Blcok和RWKV-SCCTX。
从图可以看出,其RWKV改进的地方也是变换网络和熵建模两个关键部分。两个核心设计是Bi-RWKV
Blcok和RWKV-SCCTX。
4.2 Bi-RWKV Transformer Block(变换网络)
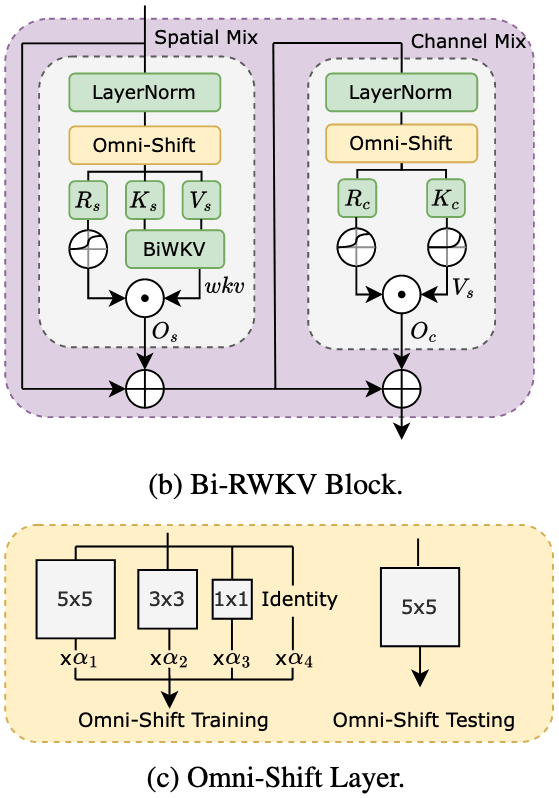
Bi-RWKV Block结构如图所示,包含两个分之:Spatial Mix,Channel Mix。
1. Spatial Mix:捕捉长距离依赖
输入:特征图f ∈ ℝH × W × C
流程如上图所示:
1)特征重塑:重构为序列X ∈ ℝT × C。
2)层归一化:保证训练稳定性
3)Omni-Shift:通过重参数化可分离5*5卷积捕获二维局部上下文,获得移位特征表示Xs
4)线性层投影:将Xs输入三个独立线性层,生成接受度Rs、键Ks、值Vs,为注意力计算提供基础参数。
5)BiWKV注意力计算:通过BiWKV注意力机制计算全局注意力权重wkv,再经过Sigmoid调制注意力贡献,最终输出Os
2. Channel Mix:增强跨通道特征融合
1)层归一化
2)Omni-Shift
3)线性投影与激活:通过线性层生成接受度Rc和键Kc,再对Kc应用平方ReLU得到值Vc
4)门控调制输出:通过Sigmoid门控的Rc动态调制Vc,筛选关键特征通道,并输出Oc
3. BiWKV Attention:源于无注意力Transformer(AFT),具有线性复杂度。
1)分别从正向和反向计算注意力权重:
正向计算时,依据K和V,结合衰减参数w和增强参数u,计算从过去到未来方向上每个token的注意力权重。反向同理。
2)正向和反向注意力计算结果进行融合,经过Sigmoid门控的接受度σ(R)进行调制,得到最终的注意力输出。
4. 有效感受野(Effective Receptive Field,ERF)
ERF主要用于描述梯度从网络中的潜在位置流向输入图像的过程,并以此定义该潜在位置能够感知到的输入图像区域。
更大的 ERF
能让网络从输入图像更广泛的区域捕获信息,这一特性对减少图像冗余尤为有利——通过感知更全面的图像信息,网络可更精准地识别并消除重复或不必要的特征,进而提升压缩效率。
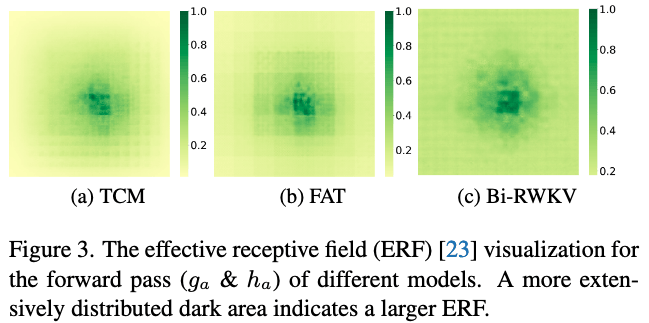 从图中可以看出,Bi-RWKV Block的感受野更大。
从图中可以看出,Bi-RWKV Block的感受野更大。
4.3 RWKV Spatial-Channel Context Model(熵建模)
提出基于RWKV的空间-通道上下文模型对潜在变量的条件分布进行建模。
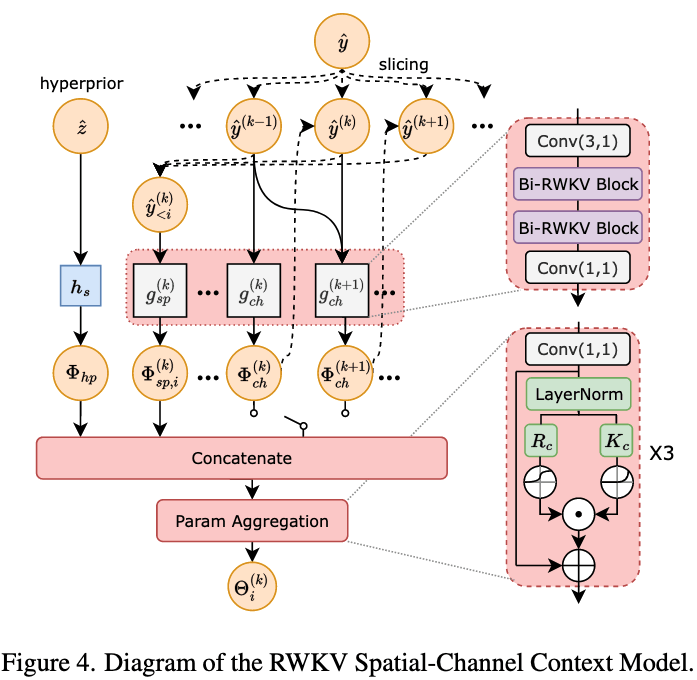
1. 空间上下文模型
使用Checkerboard方法将symbols分为两组:anchors和non-anchors。
首先对anchors编码,然后利用anchors提取到的上下文信息对non-anchors进行编码,从而捕捉依赖关系。
2. 通道上下文模型
将通道划分K个chunks来构建一个通道上下文。
由于初期的chunk承载更多的关键信息,因此为初期chunk划分更少的通道有利于精准建立条件分布。作者划分了5个chunk,分别拥有的通道数是{16, 16, 32, 64, M − 128}。
3. 流程
对于第k个的第i个symbol:
空间:使用基于checkerboard的空间上下文模型gsp(k)捕捉空间上下文特征。如果该symbol是anchor,则使用零上下文。
通道:使用基于RWKV的网络gch,利用已解码的chunk对通道上下文Φch(k)进行建模。
融合:将空间上下文和通道上下文与超先验Φhp进行拼接。在Param Aggregation中,使用Location-wise的方式融合,以预测高斯分布参数Θi(k) = (μi(k), σi(k))。
量化:对yi(k)进行量化,ŷi(k) = round(yi(k) − μi(k)) + μi(k)。
循环:得到的ŷi(k)y用于计算Φsp, (i + 1)(k)或Φch(k + 1)。
5. Experiment
5.1 Setup
- Dataset
Train:OpenImages前400k个图像
Test:Kodak,Tecnick=100,CLIC
- Results R-D曲线优于现有算法
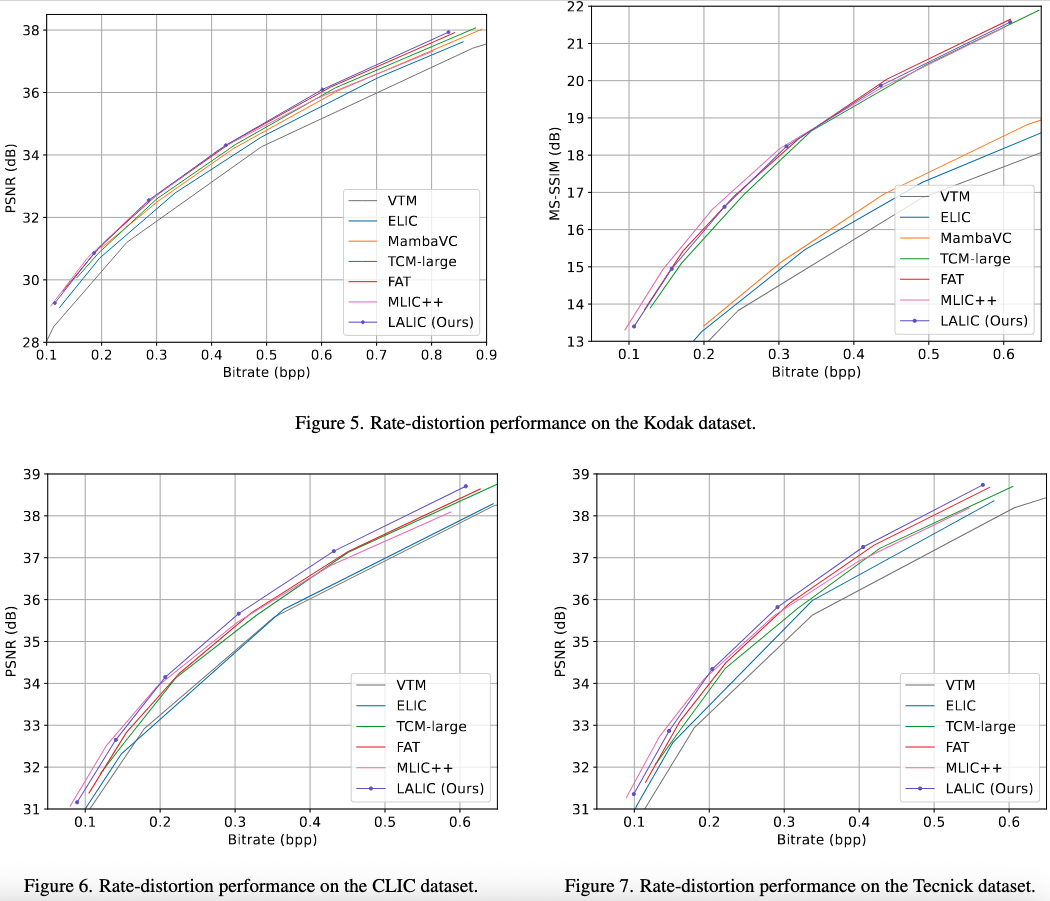
性能:DecTime、BD-Rate和Params最佳,其它次优。 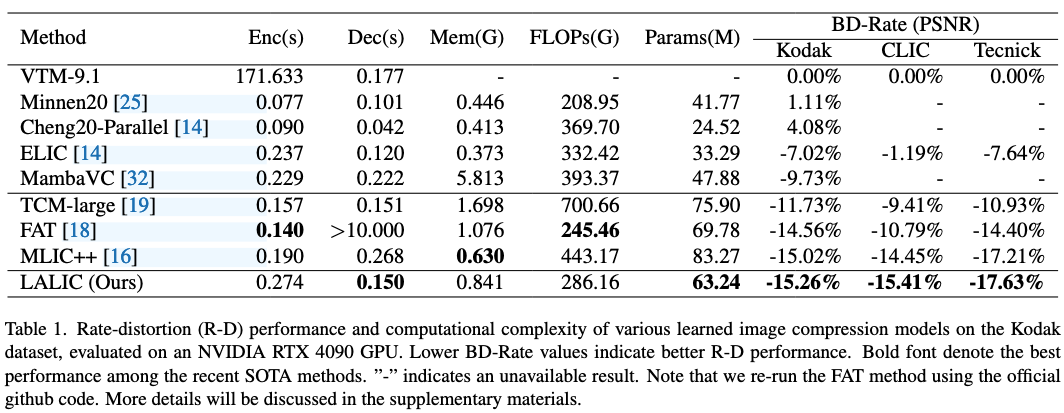
Fig.8 证明了相较于Conv,RWKV降低了潜在偏差,将关键信息集中在了初始chunk中。凸显了RWKV在平衡全局与局部依赖关系上的能力,从而实现更优的熵建模与更高效率的压缩。
Fig.9 下面一行表示周围色块与中心色块的相关性。如果相关性越低,表明Latent冗余信息越少。视觉上差别不是特别大。
6. Discussion
论文开源了,实验做的很充分,可以看一下代码。
Note
- 上下文模型:Hyperprior,Joint,Channel-Wise Autoregressive,
- Mamba是一种基于状态空间模型(State-Space Model)的序列模型。RWKV(Receptance Weighted Key Value)是一种注意力模型,其复杂度线性增长。且配备了一个token shift layer,能够有效捕获局部上下文信息。